Unity 2DでRaycast/Colliderを使わずにマウスの位置からクリックされたオブジェクトを取得する
Unity 2Dで、UIなどに対してボタンを使わずにクリック判定を実装しようと思った場合に、ググると大体以下のような手順が記載されています。
- EventSystemを追加
- 対象のオブジェクトにBox Collider2Dなどのコンポーネントをアタッチ
- Box Collider2Dのサイズをオブジェクトに合わせる
- IPointerClickHandlerインターフェースを継承したコンポーネントを作成しアタッチ
- OnPointerClickメソッド内にクリックされたときの処理を記述
実際にはコード内に一連の処理を記述できるにしても、こうして一覧にすると結構面倒に思えます。
また、このようにColliderを使ってクリック判定を行うと、2Dの場合Canvasの設定によっては期待した動作をしてくれない時があるのが困ります。
例えばUniRxで、以下のようにOnMouseDownAsObservableでオブジェクトがクリックされた場合に名前を出力するとします。
var objects = new List<GameObject>() { GameObject.Find("red"), GameObject.Find("blue"), GameObject.Find("green") }; objects.ForEach(o => { o.OnMouseDownAsObservable().Subscribe(_ => { Debug.Log(o?.name); }); });
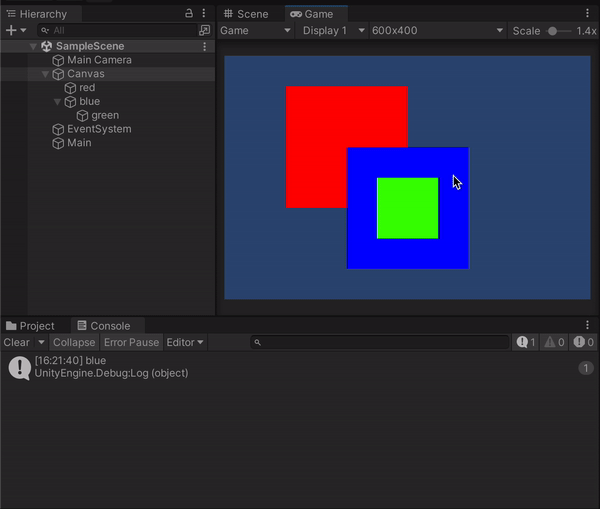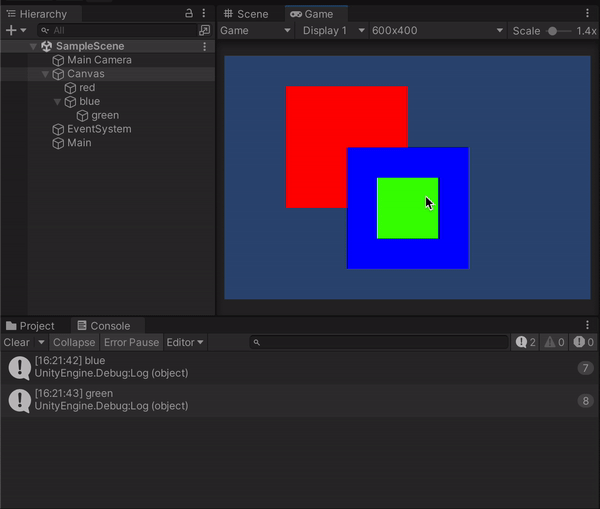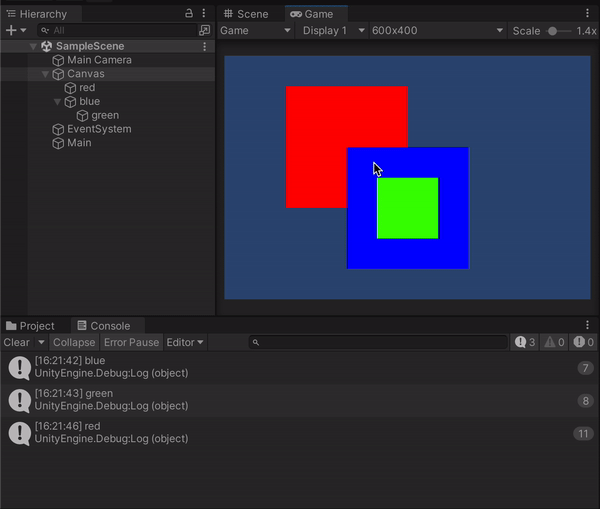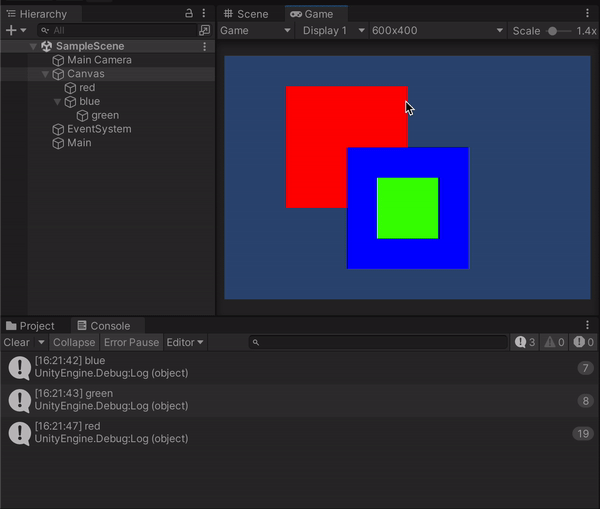
このときヒエラルキー上ではblueオブジェクトの方が下にあり、gameビュー上でもそちらの方が前面にあるように見えますが、実際にはblueとredが重なっている部分をクリックしたときに出力されているのはredのほうで、blueの子であるgreenと重なっている場合に関しても同様です。Unityの2Dは3D空間上に存在するオブジェクトを平面に投影しているだけなのでこういった事が起こるものだと思われます。試しにredオブジェクトのZ座標を変更すると、同じように重なっている部分をクリックしてもblueが表示されたりします。
OnMouseDownAsObservable の実装がどうなっているか見てはいないのですが、例えばPhysics2D.Raycastからオブジェクトを取得しようとしても同じ結果になります。
void Update() { if (Input.GetMouseButtonDown(0)) { var ray = Camera.main.ScreenPointToRay(Input.mousePosition); var hit2d = Physics2D.Raycast(ray.origin, ray.direction); Debug.Log(hit2d.transform?.gameObject.name); } }
基本的には3D向けのプラットフォームであるはずのUnityを使っているのでまぁ仕方ない部分はあるとはいえ、2Dでゲーム作っているはずなのに本来存在しないz軸等を意識する必要があるのは面倒です(オブジェクトの表示順とか考慮する必要があるにせよ)。2Dであれば直感的にゲームビュー上で見えている最前面のオブジェクト、ヒエラルキー最下層のものを取得したいような気がします。
また根本的な問題?として、クリック判定を行いたいオブジェクト全てにColliderを設定しないといけないのが手間です。Collider2Dなどはオブジェクトのサイズに合わせて勝手にサイズを調整してくれたりはしないため、オブジェクトとColliderのサイズを合わせる場合、Updateメソッド内で逐一サイズを更新したりする必要があるのは、仮にコンポーネント化するにしても面倒です。2Dゲームでマウスのクリック判定するなら「レイキャストを飛ばしてヒットしたオブジェクトを取得する」というよりも、「マウスの位置(下)と同じ位置にあるオブジェクトを取得する」という処理のほうが一般的なように思えます。
なので今回そのような処理を実装してみました。コードは以下の通りです。
using System.Collections.Generic; using System.Linq; using UnityEngine; using UnityEngine.SceneManagement; using UnityEngine.UI; namespace DefaultNamespace { public class ObjectDetector : MonoBehaviour { public void Update() { if (Input.GetMouseButtonDown(0)) { Debug.Log(GetForegroundObject()?.name); } } public GameObject GetForegroundObject() { var allGameObjects = new List<GameObject>(); GameObject[] topObjects = SceneManager.GetActiveScene().GetRootGameObjects(); topObjects.ToList().ForEach( gameObject => { gameObject.transform.GetComponentsInChildren<Transform>().ToList().ForEach(child => { allGameObjects.Add(child.gameObject); }); }); Vector2 mousePosition = Input.mousePosition; Vector3 worldPosition = Camera.main.ScreenToWorldPoint(new Vector3(mousePosition.x, mousePosition.y, 10f)); Vector3[] worldCorners = new Vector3[4]; var allGUIObjectsUnderCursor = allGameObjects .Where(gameObject => { var image = gameObject.GetComponent<Image>(); if (image == null) return false; image.rectTransform.GetWorldCorners(worldCorners); return worldCorners[0].x <= worldPosition.x && worldPosition.x <= worldCorners[2].x && worldCorners[0].y <= worldPosition.y && worldPosition.y <= worldCorners[2].y; }) .ToList(); return allGUIObjectsUnderCursor.LastOrDefault(); } } }
今回「ヒエラルキー上で下にあるオブジェクトを前面として扱う」方針のため、上のオブジェクトから深さ優先探索的にオブジェクトの並び順を考えます。
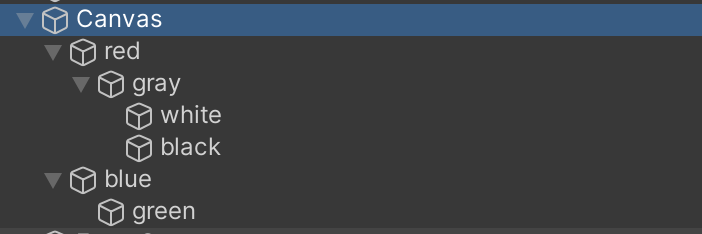
つまり、ヒエラルキー上で上のように表示されている場合、求める順番としてはこのようになります(数字が大きいほど前面にある)。
- red
- gray
- white
- black
- blue
- green
これに関しては、GetComponentInChildren がそのまま深さ優先探索となっているため、これを使えば望んだ通りの順番でオブジェクトの配列を取得する事ができます。
Component-GetComponentInChildren - Unity スクリプトリファレンス
GameObject や深さ優先探索を活用して、親子関係にある子オブジェクトから type のタイプのコンポーネントを取得します。
GetComponentInChildrenは親オブジェクトからの呼び出しになるため、SceneManager.GetActiveScene().GetRootGameObjects(); でシーン上で親を持たないオブジェクトを列挙しています。
「マウスの位置にあるオブジェクトを判定する」方法について、オブジェクトが何であるかによって範囲の取得方法が異なりますが、今回はRectTransformをもつオブジェクト、つまりuGUIのオブジェクトを対象としてます。 RectTransformの場合、GetWorldCornersメソッドがオブジェクトの4隅の座標を返すため、この範囲内にマウスカーソルが存在しているオブジェクトをリストに残し、残ったオブジェクトの最後のものがヒエラルキー上で最前面のものとして返しています。 RectTransform全てだとCanvasなども対象に含まれるため、ここではImageコンポーネントを持つものに限定しています。
RectTransform-GetWorldCorners - Unity スクリプトリファレンス
なおuGUIではなく、クリック判定するのをSpriteにしたい場合はWhere部分が以下のようになると思います。
.Where(gameObject => { var spriteRenderer = gameObject.GetComponent<SpriteRenderer>(); if (spriteRenderer == null) return false; var worldCorners = GetSpriteCorners(spriteRenderer); return worldCorners[0].x <= worldPosition.x && worldPosition.x <= worldCorners[2].x && worldCorners[0].y <= worldPosition.y && worldPosition.y <= worldCorners[2].y; }) ...
public Vector3[] GetSpriteCorners(SpriteRenderer renderer) { Vector3 topRight = renderer.transform.TransformPoint(renderer.sprite.bounds.max); Vector3 topLeft = renderer.transform.TransformPoint(new Vector3(renderer.sprite.bounds.max.x, renderer.sprite.bounds.min.y, 0)); Vector3 botLeft = renderer.transform.TransformPoint(renderer.sprite.bounds.min); Vector3 botRight = renderer.transform.TransformPoint(new Vector3(renderer.sprite.bounds.min.x, renderer.sprite.bounds.max.y, 0)); return new Vector3[] { botLeft, topLeft, topRight, botRight }; }
How do I get the positions of the corners of a sprite? - Unity Answers
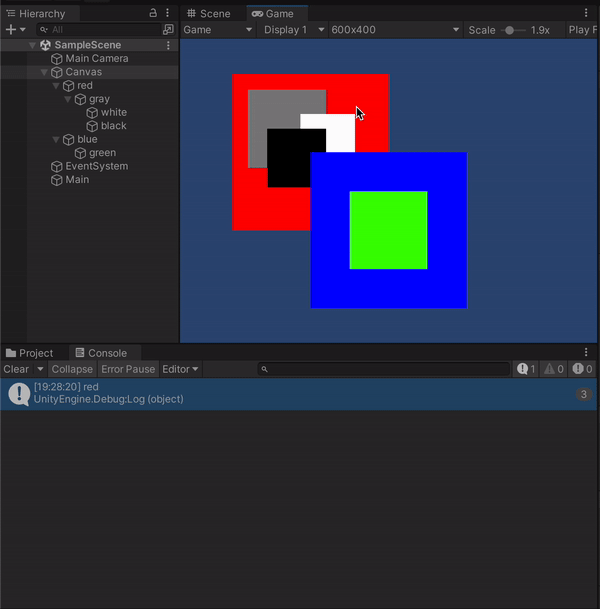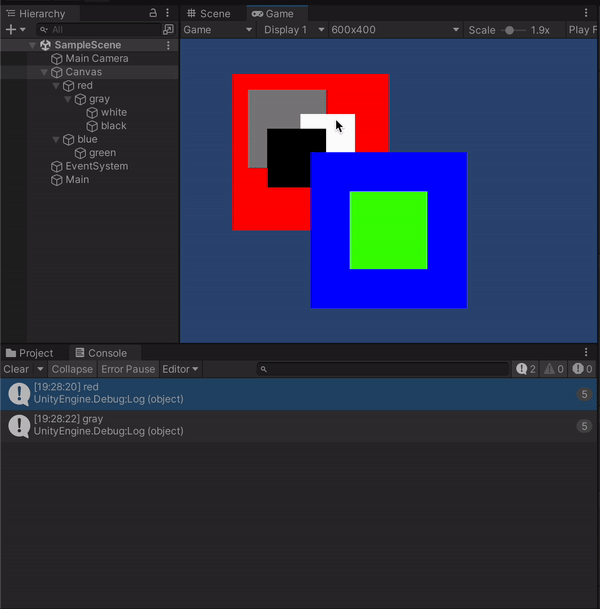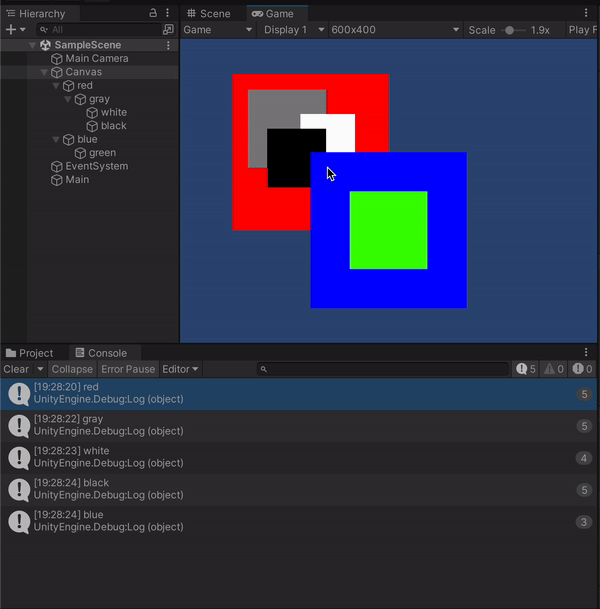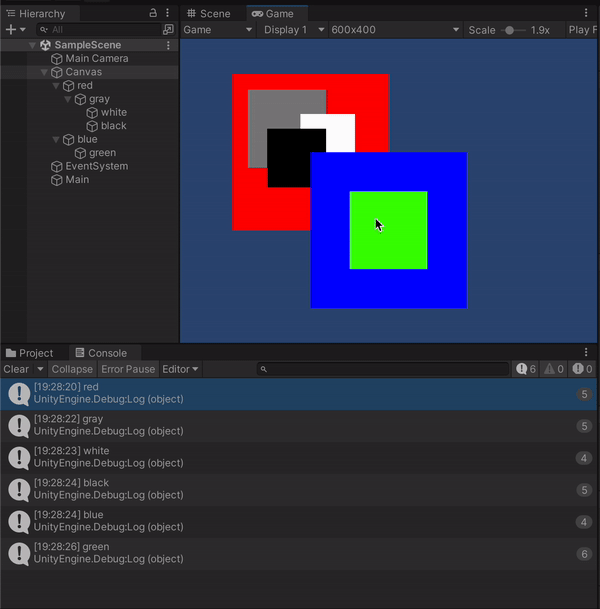
ひとまずこれで、オブジェクトにColliderや別途コンポーネントを追加することなくクリックされたオブジェクトを取得することができました。
見てわかる通り実行のたびに全てのオブジェクトを取得しておりGetComponentも多用しているのでパフォーマンス悪いと思いますがご了承ください。
おわりに
これは記事を書いている最中にわかったことなんですが、Imageコンポーネントを持つUIオブジェクトなら別にEventSystem.current.RaycastAllでよかったです。
なのでuGUIが対象の場合は全てのオブジェクトから絞ったりするのではなくそちらを使ってください。Spriteの場合も何かしら良い方法があるかもしれないですが今回はそこまで調べてはいないです。。。
あと余談ですが、マウス位置の判定部分はChatGPTで出力されたコードを一部そのまま使っています。
これは一般的な方法を確認する目的で質問してみた結果なのですが、そのまま使えるコードが出力されるのには驚きました。
質問内容を工夫すれば記事と同じ内容のコードも出力できるかもしれません。もう人間いらないかもしれない

E.G.G. Japan体験記/Google Professional Cloud Architectの認定資格を取得しました
今回の記事では、E.G.G. Japan(Expert of GCP for Gaming Japan)というGoogle主催のオンラインセッションに参加し、その流れでProfessional Cloud Architectの認定資格を取得したというお話について書きたいと思います。
Professional Cloud Architect 認定資格 | Google Cloud

E.G.G. Japanに関して
E.G.G. Japanに関してはすでに別の方が記事を書いていらっしゃるので、詳しい説明などはそちらに譲りたいんですが、E.G.G. Japanとは「ゲーム業界で働くエンジニア向けの学習プログラム」となっており、公のものではなく招待制の形をとっています。
参加の経緯としては、社内SlackにGoogleの方とやりとりする用のチャンネルがあるのですが、そこで自分の会社の方に招待を頂き、それに対して自分が参加を希望したという感じです。ゲーム業界に対しては常々興味を抱いているため、社内のエンジニア向け通知でこのお知らせを聞いた時は、参加可能な人数が限られているという点もあり「これは行かなければ」と思い急いで申し込んだのですが、結果的には社内で希望を出したのは自分一人だったみたいです。
実際に参加してみると、E.G.G. Japanは一応ゲーム業界向けのプログラムと銘打ってはありますが、ゲーム業界で働いている方の実務に役立つ内容というよりは、単純にGCPの認定資格取得に向けた勉強会みたいな感じでした。参加されている方に関しても7割くらいは実際にゲーム業界の方でしたが、自分を含めそれ以外の分野を主とする会社から参加されている方も多くいらっしゃいました。
ちなみに上に挙げた記事のほうでは「事前にGoogle Cloudさんのチェックを通したものを掲載」となっているのですが、プログラムの期間が終わっているのもあり自分はそこまでやっていないため、この記事以上の内容を書くつもりはない(というか書けない)です。なので一部を除いて画像とかもありません。ただE.G.G. Japanで調べて記事がほとんどヒットしないというのもあれなんで、一応体験記として感想くらいは残しておきたいと思います。あとPCA認定資格についても書ければなと。
プログラムに関して
プログラムは4月~7月にかけて行われ、8月に修了式が行われます。修了条件としては、
- 全3回のオンラインセッションに参加
- 指定されたGoogle Cloud認定資格(Professional Cloud Architect/Developerのいずれか)の試験に合格する
が与えられており、これを満たすと修了式で表彰が行われるというものです。プログラム全体としては、Courseraのアカウントが与えられ各々で学習を進めながら、合間にオンラインセッションを挟みつつ最終的に試験の合格を目指すという流れです。
オンラインセッションに関してはGoogleのエンジニアの方々がGoogle Cloudの主要サービスについて説明し、その後実際にハンズオンで手を動かしながら理解を深めるという形でした。全3回ということで自分としてはやや回数に物足りなさを覚えるものでしたが、その分内容は非常に充実していました。覚えている限りではCloud Spanner、Cloud Runなどのサービスについて行ったハンズオンが印象に残っているのですが、どちらもサービスの利点が伝わるような内容で実際に使ってみたくなるようなもので、そういう意味ではGoogle側の営業戦略としての本プログラムは自分にとって非常に効果的だったと思います。
あと、参加者同士の懇親会みたいなのがあって、プログラムに参加する前はゲーム業界のお話が聞けるチャンスだと思っていたのですが、懇親会に申し込みするのを忘れていて自分は参加できませんでした‥‥
セッション中でわからなかったことや、その他学習において困ったことなどをチャットGoogleの方相談できるなど、サポートも丁寧でした。細かい疑問なども含めて実際に多くの参加者がこれを活用しており、冒頭の記事でもありますが特に質問数の多かった方、またチャットにスタンプをつけた数が多かった方などが特別賞として修了式で表彰されていました。そういった点からも伺えるように、全体を通して主催者側の参加者のモチベーションを保とうとする姿勢が大変好印象でした。
試験について
修了要件とされているGoogle Cloud認定資格に関してはProfessional Cloud Architect/Developerのいずれかを選べるのですが、調べた感じ後者の方が難易度が高そうだったので前者を選びました。ただ、こちらは今年で言えば7/15までに合格証明を事務局に提出する必要があるんですが、正式な合格通知が出るまで7~10日程度かかるため、実質的に6月中~7月1週目くらいがデッドラインになっています。自分は7/3に受験し10日に合格通知が届きました。

試験は試験会場に出向くかオンライン形式での受験が選べ、自分はオンラインで受験しました。オンライン受験に関しては、結構知らないと何をしていいか迷う場面が多いと思います。まず試験前に専用のブラウザをPCにインストールしておく必要があり、時間になったら試験ページにログインして受験するんですが、英語交じりのチャットで「名前を読み上げてください」と指示されたり、あと周りに何もないことを示すためにPCのwebカメラを四方の壁に向けるように指示されたりします。自分は事前にある程度知識を入れておいたので、周りに何もない場所にローテーブルだけ用意してノートPCで受験しましたが、特にデスクトップPCで外付けのwebカメラを利用して受験する場合とかは焦るだろうなとか思いました。
試験は120分、全50問で4択または5~6個のうち2,3正解を選ぶ形式になっています。後述しますが、試験自体はめちゃくちゃ簡単でした。120分中にすでに解いた問題を見直したり解答を修正したりできますが、終了を待たずとも解答を提出することができます。前述の通り正式な通知が来るのは後になりますが結果自体はその場でわかります。点数とかは公表されませんが、特に問題なく合格できました。
修了式
水曜日(8/3)に修了式がありまして、試験に合格した参加者の名前などが表彰されました。今回のプログラムでは半数以上の方が合格されたそうです。またCourseraのコースの修了はプログラムの修了条件には含まれていないのですが、特に修了したコースの多かった方などは別で表彰されていました。終わったあとにもオンライン形式の懇親会があったんですが、自分は参加していないです(コミュ力が足らず‥‥)
試験対策/試験の難易度について
これ、どこまで書いていいかちょっとよくわかってないのですが‥‥肝心の試験について、先ほど簡単だったと述べましたが、当然これには理由がありまして、実をいうと試験を受ける前に出題される問題はほとんど予測できるからです。全50問と書きましたが、実際には出題される問題のパターンがほとんど決まっていて、全部で180~200くらいある問題のうちからそっくりそのまま50個出題されるだけです。過去問自体は公表されていませんがネットを探せば転がっているため、その辺の問題を全部覚えればほとんど問題なく合格できてしまいます。元々そのことを知っていたわけではないんですが、一週間くらい前に模擬試験を受けると見たことのある問題ばかりであり、同じタイミングで購入したUdemyの日本語解説つきの問題集に関しても同様だったため、そういうことなんだなと。実際、本番の試験ではわからない(というより、見たことがない)問題がほぼなかったです。ただUdemyに関しては、他サイトでは正解の選択肢が曖昧だったりするものに対してしっかり日本語の解説がついているため購入する意味はありました。
自分は1ヶ月前くらいから本格的に勉強をはじめて、問題など見つつ公式ドキュメントを読み込んだりしていたのですが、ドキュメントに関してはほとんど読む必要がなかったです。Courseraも実際に手を動かす必要があるため結構時間がかかるんですが、直接的な試験対策になるかというと微妙なところでした。実際、表彰式では参加者代表として一番初めに試験の合格報告を行った方が挨拶されていたのですが、ドキュメント丁寧に読み込んだけど最初の問題からわからなかった、と話されていました。実際には先に書いた通り、知識がなくても問題の答えだけ暗記した方が有利であり、真面目に知識を詰め込んだ人が損をするような形式になっているのはいかがなものかと思います。
おわりに
E.G.G. Japanに参加して認定資格を取得したというお話でしたが、プログラム自体はサポートも手厚く非常に価値のあるものでした。ただそれだけに最終目標に設定されている認定資格のあり方には疑問が浮かぶというか‥‥少なくともクラウドの知識が一切なくても合格できるような感じなので、自分としてはこれが実務に役立つかと聞かれたらそうとは言い切れないかもしれません。ただ、プログラムに参加しなければGCPの資格自体取る機会もなかっただろうと考えると、結果的には良かったのだと思います。最後にプログラム修了の記念品としていただいたパーカーの写真だけ載せて終わりにしたいと思います。

【Unity】スクロールビューに配置された要素の上でマウスホイールによるスクロールができない問題を解決する
概要
Unityにデフォルトで用意されているGUIのScroll Viewについて、これは名前の通り限られた表示領域に多くのオブジェクトを配置できるスクロール可能なレイアウト用オブジェクトですが、
これはデフォルトの状態だとマウスホイールでスクロールすることが可能です。(正確にはScrollRectコンポーネントのMovement TypeがElasticの場合にこうなるみたいです)
で、これを使っていてタイトルの件に遭遇したので原因と解決策のメモ書きです。
文字だけだとよくわからないので具体的には以下のgifを見てもらうとわかるかと思います。

わかりやすいようにScrollRectのScroll Sensibilityの値を上げてスクロール量を増やしていますが、Scroll View内に配置されているボタンの上にマウスカーソルがあるとき、ホイールによるスクロールが効いていないのが見て取れると思います。
原因と対応
これの原因なんですが、Scroll Viewに(正確にはScroll View内のContent Areaに)配置されている子オブジェクトに以下のコンポーネントがアタッチされているとき、そのオブジェクトがマウスのraycastをブロックすることにより発生するようです。
- EventTrigger
- ImageなどのRaycast Targetになるコンポーネント
色々試したんですが対応としては、スクロール中は上記いずれかを無効にするしかないみたいです。他にいい解決策があるような気はしていますが‥‥
using UnityEngine; using UnityEngine.EventSystems; public class ScrollableImage : MonoBehaviour { [SerializeField] private int _threshold = 20; [SerializeField] private bool _enabled = true; private int _frameCount; private EventTrigger _trigger; private void Start() { _trigger = gameObject.GetComponent<EventTrigger>(); } private void Update() { if (!_enabled) return; if (Input.GetAxis("Mouse ScrollWheel") != 0) { _frameCount = 0; _trigger.enabled = false; } if (_frameCount >= _threshold) { _trigger.enabled = true; } else { _frameCount++; } } }
上記スクリプトをScroll Viewの子要素にアタッチするとホイールによるスクロールが効くようになります。
マウスホイールの入力自体は Input.GetAxis("Mouse ScrollWheel") で取得できるため、この入力があったときは一時的にEventTriggerを無効にしています。
_threshold という変数を用いている理由については、マウスホイールの入力は連続的ではないため、ここでは20フレームとしていますがある程度の閾値を挟まないといい感じの挙動にならなかったためです。
EventTiggerではなく、オブジェクトのRaycast Targetを無効にすることでも対応できます。
ボタンなどではボタン自体のImageだけでなく子要素のTextもRaycast Targetとなるため、自身を含む子要素すべてを無効にする必要があります。
違いがあるのかはわかりませんが、特に理由がなければ上記のEvent Triggerを無効にするほうで問題ないかと思います。
using System.Collections.Generic; using System.Linq; using UnityEngine; using UnityEngine.UI; public class ScrollableImage : MonoBehaviour { [SerializeField] private int _threshold = 20; [SerializeField] private bool _enabled = true; private int _frameCount; private List<Graphic> _imageComponents; private void Start() { _imageComponents = new List<Graphic> {gameObject.GetComponent<Graphic>()}; _imageComponents = _imageComponents.Concat(gameObject.GetComponentsInChildren<Graphic>()) .Where(i => i != null).ToList(); } private void Update() { if (_imageComponents.Count == 0 || !_enabled) return; if (Input.GetAxis("Mouse ScrollWheel") != 0) { _frameCount = 0; foreach (Graphic graphic in _imageComponents) { graphic.raycastTarget = false; } } if (_frameCount >= _threshold) { foreach (Graphic graphic in _imageComponents) { graphic.raycastTarget = true; } } else { _frameCount++; } } }
ちなみにマウスホイールの入力検知は EventTriggerType.Scroll というのがあるのでそちらでもできますが、特にホイール入力が終わったときにどうこうできるものでもないためいずれにせよ工夫が必要みたいです。
参考
child objects blocking scrollrect from scrolling - Unity Forum
IDragHandler on child blocks Scrollrect scrolling - Unity Forum
【Kotlin】Apache PDFBoxの使い方 ~複数画像のpdf化、pdfの暗号化など~
皆さんPDFはお好きですか。変な質問かもしれませんが、自分に関して言えばこのPDFというファイルの形式はかなりお気に入りで、というのも自分がそれなりに愛用しているノートアプリのEvernoteがとにかくPDFの保存と整理に長けており*1、学生時代は参考論文をすべてEvernote+PDFで管理していたことから、それ以降書類とか資料とかをとにかくPDFにして管理したがる癖がついてしまっているからです。
PDFの加工に関してはこういうWebサービスだったり、
Adobeが提供している何たらを使う方法がありますが、いかんせん主要な機能を使うには無料ではできなかったりとあれなんで、自分で作ってみることにしました。言語はKotlinで、Apache PDFBoxというライブラリを使います。Kotlinはモダンな言語仕様に加えて元がJavaなんで、Javaの豊富な資源が使えるのがとてもいいと思います。
導入方法
gradleかMavenで導入します。
dependencies {
implementation('org.apache.pdfbox:pdfbox:2.0.4')
}
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.4</version>
</dependency>
基本の使い方
以下は新しいpdfを作成する例になりますが、PDDocumentがpdfを表す基本クラスで、PDPageがページに相当するクラスになります。doc.save(filePath)でpdfを保存し、作業が終わったら最後にdoc.close()で閉じる必要があります。
fun main() { val doc = PDDocument() val page = PDPage(PDRectangle.A4) doc.addPage(page) // .... // ページに対する処理など // .... doc.save("test5.pdf"); doc.close(); }
ページに対して文字や画像などを挿入するには、そのページに対するPDPageContentStreamクラスのインスタンスを利用する形になります。
val stream = PDPageContentStream(doc, page) stream.beginText() stream.setFont(PDType1Font.HELVETICA, 20f) stream.moveTextPositionByAmount(100f, 100f) stream.drawString("test") stream.endText() stream.close()
この例では指定したページに対して左下から(100,100)ピクセルの位置に"test"という文字を入れています。
また既存のpdfを読み込む場合は以下のようになります。
val doc = PDDocument.load(File(filePath))
以下ではこれを基本に具体的なサンプルについて説明します。なお実装は以下のサイトを参考にしています。
サンプル① 複数の画像をまとめてpdfにする
今回特にやりたかったのはこれです。同様のことは最初に上げたiLovePdfでもできるのですが、無料の範囲内では一度に作成できる数に制限があったりします。
これをPDFBoxで実装するとこんな感じになります。各画像に対して、その画像と同じ大きさのページを作って追加していくという感じです。順番に関しては別途ソート処理を入れるとかになると思います。
/** * 指定ディレクトリ以下の画像をまとめて一つのPDFにして保存 */ fun createPdfFromImages(resourceDirPath:String, outPutFilePath: String) { val doc = PDDocument() val resourceDir = File(resourceDirPath) resourceDir.listFiles { f -> f.isFile }.forEach { println("ページ追加:$it.path") var pdImage = PDImageXObject.createFromFile(it.path, doc) var page = PDPage(PDRectangle(pdImage.image.width.toFloat(), pdImage.image.height.toFloat())) doc.addPage(page) var stream = PDPageContentStream(doc, page) stream.drawImage(pdImage, 0f, 0f) stream.close() } doc.save(outPutFilePath) doc.close() }
使い方
createPdfFromImages("./resources", "merged.pdf")
ここではプロジェクト直下のresourcesディレクトリ以下の画像をmerged.pdfに結合しています。
サンプル② PDFの結合
pdfの結合にはPDFMergerUtilityというクラスを使います。
/** * 読み込んだ複数のpdfファイルを結合 */ fun mergePdfFiles(files: List<File>, outPutFilePath: String) { val merger = PDFMergerUtility() merger.destinationFileName = outPutFilePath files.forEach() { merger.addSource(it) } merger.mergeDocuments() }
使い方
val file1 = File("test1.pdf") val file2 = File("test2.pdf") mergePdfFiles(listOf(file1, file2), "merged.pdf")
サンプル③ PDFの分割
pdfの分割はちょっとややこしいです。というのも、SplitterというクラスのsplitメソッドはPDDocumentをページごとに分割して返すというものなんですが、これの戻り値がPDPageのリストではなくPDDocumentのリストになっているため、返ってきたリスト内のpdfを再度結合するには一工夫いります(PDFMergerUtilityはソースにFileクラスを取り、PDDocumentをそのままでは結合できないため)。
なので、例えばあるpdfを2つに分割したいという場合は以下のようにします。もっと効率のいいやり方があるかもしれません。
/** * 複数のPDDocumentを結合 */ fun mergePDDocuments(docs: List<PDDocument>): PDDocument { val merged = PDDocument() docs.forEach { doc -> doc.pages.forEach { page -> merged.addPage(page) } } return merged } /** * PDDocumentを指定されたページ以下から分割して保存する */ fun splitIntoTwo(doc: PDDocument, pageNumber: Int) { val splitter = Splitter() val list = splitter.split(doc) val docs1 = list.subList(0, pageNumber - 1) val docs2 = list.subList(pageNumber, list.lastIndex) val doc1 = mergePDDocuments(docs1) val doc2 = mergePDDocuments(docs2) doc1.save("split_0.pdf") doc2.save("split_1.pdf") doc1.close() doc2.close() }
使い方
val doc = PDDocument.load(File("test.pdf")) // 2ページ以下から分割 splitIntoTwo(doc, 2)
サンプル④ pdfの暗号化
windowsを使う大体の人がpdfリーダーとして使っている(?)adobeのpdf Readerには暗号化機能がなく、冒頭で述べた通り有料版のAdobe Acrobatを使う必要があるため、無料でできる暗号化には意外と需要がありそうな気がします。
PDFBoxでの暗号化は以下のようにします。
/** * PDFを暗号化 */ fun encryptPdf(doc: PDDocument) { val accessPermission = AccessPermission() val spp = StandardProtectionPolicy("1234", "1234", accessPermission) spp.setEncryptionKeyLength(128); spp.setPermissions(accessPermission); doc.protect(spp); }
使い方
val doc = PDDocument.load(File("test.pdf")) encryptPdf(doc, "password", "password")
ここでは所有者パスpassword、ユーザーパスpasswordでtest.pdfを暗号化しています。なお前者は編集権限のパス、後者はドキュメントを開く際のパスっぽいです。
なお、そのままだとdoc.protect()を実行した際にエラーが出ます。
Exception in thread "main" java.lang.NoClassDefFoundError: org/bouncycastle/jce/provider/BouncyCastleProvider
以下に解決策が載っていました。
その他できること
自分の用途では上の例くらいで間に合うのですが、他にもPDFからの画像の取得、またテキストの読み取りなんかもできたりするみたいです。気になった方は公式サイトか上に上げたチュートリアルのサイトなど見ていただければと思います。
おわりに
サンプルコードは以下にまとめてあります。
追記
書き終わった後に気づいたんですが、複数画像をまとめてpdf化するならImagemagickでいける上、そっちのほうが出力されるpdfの品質が高いです‥‥。まぁこれも勉強ということで。 higuma.github.io
M1チップ搭載Macにccat + enhancdを入れる
前置き
一ヶ月くらい前の話なんですが、最近新型Mac Miniを買いました。M1チップ搭載のやつです。もともと使ってたWindows機は10年くらい前のHPのワークステーションを中古で買ったもので、パーツを取り替えたりした後は特に問題もなく使っていたのですが、さすがに古くなってきて音もうるさいし思ったより消費電力も大きそうだったので買い替えを検討していたところ、AppleのM1チップがスゴいらしいぞという話を耳にして、10万かそこらでこの性能なら買い!と思ったので買ってしまいました。ほとんど衝動買いに近いです。
買ってみて思ったのは、デスクトップ環境で使うのであればWindowsもMac OSも大して変わらないのではということです。仕事でMacbookを使うようになり、その使いやすさに驚き「Macめっちゃええやん、Windows(笑)」となっていたのですが、いざデスクトップ用Macを買ってみるとこれはこれで問題(というほどでもないですが、気に入らない点)がそこそこあって、期待していたほどの感動みたいなのはなかったです。Steamのゲームが動かないのは百も承知だったんですが、ロジクールのマウスのドライバがうまいこと動いてくれなかったのは困りました。Macが使いやすいというかMacbookが使いやすいんだなぁと再認識しました。
前置きが長くなりましたが、Mac OSで個人的には必須ツールとして使っているenhancdというツールがあって、M1 Mac特有のあれこれでインストールに苦労したので布教を兼ねて導入手順を買いておきます。
enhancdとは
ターミナルのディレクトリ移動を高速化&快適にするものです。詳しくは作者さんの記事を読んでいただければわかると思います。
はっきり言ってしまうとこれは神ツールです。Mac使いの人はターミナルをカスタマイズする方が多いと思うのですが、自分はめんどいのでこれ一本(と簡単なシェルスクリプト)でやっています。逆にいうとこれさえあればターミナルでの作業は特に問題なく行えると思います。知らない人はぜひ一度使ってみていただければという感じです。
余談ですが、Macに買い替えた最大の理由は上記プラグインの存在などもあり、Windowsのコマンドラインが(cmderなどのツールを使っても)Macに比べ使いづらかった点があります。が、最近Windows Consoleとかいうのが出たりWSLが新しくなったりして、Windowsでもbashが使える!と思って導入してみたのですが、思っていた以上にWSLが意味不明な出来だったので別にそうでもなかったです。
導入方法
少し前からMacのターミナルはzshがデフォルトになっていますが、自分はbashを使っているので以下ではbashでの作業を想定しています。zshの場合は適宜読み替えていただければと思います。
homebrewを入れる
まず各種ライブラリ等を導入するのに必要なHomebewを入れます。公式サイトに乗っているインストールコマンドをターミナルに流すだけです。
macOS(またはLinux)用パッケージマネージャー — Homebrew
もしかしたらインストールに失敗するかもしれませんが、そのときは以下のような対応が必要になると思います。よくわかってないですが自分は一応設定しています。
インストール後、以下のように示されるのでecho~とeval~から始まるコマンドを忘れずに入力しておきます。
==> Next steps:
- Add Homebrew to your PATH in /Users/username/.zprofile:
echo 'eval $(/opt/homebrew/bin/brew shellenv)' >> /Users/username/.zprofile
eval $(/opt/homebrew/bin/brew shellenv)
またeval $(/opt/homebrew/bin/brew shellenv)のほうは後で必要になるのでメモっておきます。
ccatを入れる
enhancdのインストール過程でccatというツールが必要になるのですが、これをbrewコマンドで入れようとすると失敗します。表示されるコマンドをあれこれ試していると以下のようなエラーが出て止まります。
go: cannot find main module; see 'go help modules'
仕方がないので、ソースコードを直接ビルドします。
ここでGOPATHというものを通す必要があります。go言語全然知らないのであれなんですが、goは全ての作業ディレクトリを一つのディレクトリ(ワークスペース)以下に配置するのが基本らしく、それを用意する必要があります。
まず好きな場所にgo用のディレクトリを作ります。自分は/Users/username/goにしました。
ディレクトリを作成したら、.bash_profileに以下を追記します。
export GOPATH=/Users/username/go export PATH=$GOPATH/bin:$PATH
source ~/.bash_profileを実行した後、echo $GOPATHで指定した場所が表示されることを確認しておきます。go env GOPATHでもいいです。
その後、以下のコマンドでccatをインストールします。
go get -u github.com/owenthereal/ccat
終わったらccatコマンドが認識されていることを確認します。
参考:
Golang 1.11でGO111MODULE=onの状態でグローバルにgo getできない時の対処法 - Qiita
Go のワークスペースの考え方 (GOPATH) | まくまくHugo/Goノート
enhancdのインストール、.bash_profileの編集
いよいよenhancdをインストールします。といっても基本はシェルスクリプトなのでダウンロードしてパスを通すだけです。
cd ~ git clone https://github.com/b4b4r07/enhancd chflags hidden enhancd #任意 echo "source ~/enhancd/init.sh" >> ~/.bash_profile source ~/.bash_profile
で、色々やっているとなぜかbrewコマンドとかgoコマンドなどが認識されなくなったりします。理由はよくわからないんですが、Homebrewインストール時に表示されるeval $(/opt/homebrew/bin/brew shellenv)を再度実行すると直ったので、これも.bash_profileに追記しておきます。
最終的には.bash_profileの内容は以下のようになっていると思います。
export GOPATH=/Users/nomurashunta/go export PATH=$GOPATH/bin:$PATH eval $(/opt/homebrew/bin/brew shellenv) source ~/enhancd/init.sh
これで作業は完了です。
cd -と入力して移動先ディレクトリの候補一覧が表示されることを確認します。
追記:Linux(WSL)編
上でMac購入がどうたら書いたんですが、実は購入後半年もしないうちに売却してしまいました。理由は自分が普段使っているアプリのMac版(Clip Studio PaintやUnityなど)の挙動が、どうも自分が想定していた以上にWindowsのものと異なっており、いくら慣れが必要と言ってもその違和感を抱えたまま使い続けることは難しいなと思ったからです。特に前者はWindows版に比べるとMac向けアプリの性質上かは知りませんが、これじゃない感がすごく強い上、根本的な問題として最新のドライバーを入れているにも関わらず使っているペンタブレットの書き味みたいなのがWindowsと大きく異なったため、実質的にこれが決定打となりました。加えて言うとロジクールのマウスのドライバーが使えなかったのも理由として大きかったです。
ともかく、売ったお金でWindows機を買い替え(中身自体は据え置き)、これを機にWindowsでの開発環境を整えるかという事で、手始めにWSLをもう少し触ってみるかということで、それならやはりenhancdはどうしても欲しいということで、WSLのLinuxに導入してみたメモを残します。
Linuxにenhancdを導入する
上述の通りenhancd本体はシェルスクリプトなので、Macではhomebrewで入れていたfzyとccatを導入できれば動くはずです。 まずgoを入れ、上に書いた通りの方法で直接ccatをインストールします。。
続いてfzyを直接コンパイルして使えるようにします。そのまま入れようとするとmakeとgccが足りないと怒られるので入れておきます。WSLの問題かはわかりませんが、sudo apt-get updateを実行しないと404みたいなエラーが出るので更新必須です。
sudo apt-get update sudo apt-get install make sudo apt-get install gcc
これが終わったらfzyのリポジトリからソースをダウンロードし、コンパイルします。
git clone https://github.com/jhawthorn/fzy.git cd fzy sudo make sudo make install
fzyコマンドが認識されているのを確認したら、あとはenhancdを入れるだけです。
cd ~ git clone https://github.com/b4b4r07/enhancd chflags hidden enhancd #任意 echo "source ~/enhancd/init.sh" >> ~/.bash_profile source ~/.bash_profile
cd -でフォルダの一覧が表示されることを確認します。
ちなみに自分はmacを使う場合enhancdでターミナル上からディレクトリを移動し、GUI操作が必要な時はopenコマンドで開くのが基本なのですが、WSL上でのopenコマンドはexplorer.exeに相当します。いちいち打つのは面倒なので適当にエイリアスなど設定しておくとよいと思います。
alias open='explorer.exe $@'
が、残念なことにexplorer.exeは完全ではなく、例えば以下のコマンドでホームディレクトリを開こうとすると、なぜかドキュメントフォルダが開きます。存在しないディレクトリを指定しても同じくドキュメントが開きます。
explorer.exe ~/
あと気付いたのですが細かい点として、cd cとするとcドライブ直下(/mnt/c)に移動できるのですが、VS CodeのCLIツールでファイルを開くcodeコマンドを実行する際、/mnt/c以外のディレクトリにいるときにcode ~/aaa.txtとした場合は/Ubuntu-20.04/home/username/aaa.txtが開くにも関わらず、/mnt/cにいるときにcode ~/aaa.txtとするとc:/home/username/aaa.txtが開きます。よくわかりません‥‥。
【Unity】Resouce.Load以外から画像を読み込んでSpriteに変換する
Unityでファイルから画像を読みこんで GUIのImageコンポーネントなどに設定するには、通常は以下のようにすると思います。
var sprite = Resources.Load<Sprite>("image_xxx"); var image = GameObject.Find("SomeSprite").GetComponent<Image>(); image.sprite = sprite;
で、読み込む画像がResourcesフォルダ配下にある場合はいいのですが、そうではない場合どうすればいいかについて調べたところ、意外と情報が見つからなかったのでメモっておきます。
(話はそれますが根本的に Resource.Load は使わないほうがいいらしいです。詳細は以下の記事などが詳しいと思います。)
light11.hatenadiary.com
Resouce.Loadを使わないSpriteの読み込み
表題の件について結論から言うと、 System.IO.File.ReadAllBytes で読み込んだ画像データをTexture2Dに設定し、Sprite.Create でSpriteに変換するのがよいみたいです。
public static Sprite LoadSprite(string path) { try { var rawData = System.IO.File.ReadAllBytes(path); Texture2D texture2D = new Texture2D(0, 0); texture2D.LoadImage(rawData); var sprite = Sprite.Create(texture2D, new Rect(0f, 0f, texture2D.width, texture2D.height), new Vector2(0.5f, 0.5f), 100f); return sprite; } catch (Exception e) { return null; } }
そもそもなぜこのような処理が必要かというと、例えばゲーム内で保存した画像を再度読み込んで使いたい場合があるとします。
例えばノベルゲーム他で、セーブ画面に必要な画面のスクリーンショットを撮る場合とかです。
スクリーンショット自体は ScreenCapture.CaptureScreenshot で撮れるんですが、撮った画像はResourcesフォルダじゃなくて、他に作ってあるSaveDataフォルダに保存しておきたい…みたいな場合に使えると思います。別に全部Resources配下に保存してもいいのですが…。
ちなみに ScreenCapture.CaptureScreenshot ですが、これは別に画像の保存が完了するまで処理を待ってくれたりはしません。
もちろん実行中の処理がブロックされては困るため仕様としては正しいはずなんですが、例えば以下のようにスクリーンショットを保存した後、続けてそれを読み込んでもnullになって帰ってきます。
ScreenCapture.CaptureScreenshot(SAVE_FILE_PATH_1); var sprite1 = LoadSprite(SAVE_FILE_PATH_1);
実際にはコルーチンなど使って少し処理を待つ必要があります。
#if UNITY_EDITOR private readonly string SAVE_FILE_PATH_1 = "Assets/SaveData/screen_shot1.png"; private readonly string SAVE_FILE_PATH_2 = "Assets/Resources/screen_shot2.png"; #else private string SAVE_FILE_PATH_1 = $"{Application.dataPath}/SaveData/screen_shot1.png"; private string SAVE_FILE_PATH_2 = $"{Application.dataPath}/Resources/screen_shot2.png"; #endif private IEnumerator TakeScreenShotAndDisplay() { ScreenCapture.CaptureScreenshot(SAVE_FILE_PATH_1); yield return new WaitForSeconds(0.1f); ScreenCapture.CaptureScreenshot(SAVE_FILE_PATH_2); yield return new WaitForSeconds(0.1f); var image1 = GameObject.Find("Save1").GetComponent<Image>(); var sprite1 = LoadSprite(SAVE_FILE_PATH_1); image1.sprite = sprite1; var sprite2 = Resources.Load<Sprite>("screen_shot2"); var image2 = GameObject.Find("Save2").GetComponent<Image>(); image2.sprite = sprite2; }
Unityではたまに1フレーム待たないとスクリプト上での処理が反映されないみたいな場合があって(GameObjectをDestroyするときなど)、そういうときにはコルーチン内でyield return null とかする必要があるのですが、上の例では yield return null としても、保存処理が間に合わないのか撮ったスクリーンショットが読み込めません。
実際のところ ScreenCapture.CaptureScreenshot を呼び出してからどのくらい待てばよいか?というのは自分にはよくわかりません。もし本当に撮ったスクリーンショットを即時使いたいという場合は以下のようなコードが必要になると思います。
kan-kikuchi.hatenablog.com
あと、上の例では SAVE_FILE_PATH_1 に保存した後0.1秒待っていますが、これをやらないと SAVE_FILE_PATH_1 に画像が保存されなかったりします。
例えば以下のように続けてスクリーンショットを撮ると、SAVE_FILE_PATH_2 には画像が保存されますが SAVE_FILE_PATH_1 には保存されません。何故かはわかりません。誰か理由知ってたら教えてください。
ScreenCapture.CaptureScreenshot(SAVE_FILE_PATH_1); ScreenCapture.CaptureScreenshot(SAVE_FILE_PATH_2);
CloudFrontでS3のコンテンツをキャッシュし、Lambda@Edgeでブラウザキャッシュを有効にする
仕事でCloudFrontに触る機会があったので復習兼メモ書きです。AWS始めたてなので色々間違ってる部分があるかもしれませんがご了承ください。
CloudFrontとは
CloudFrontは一言で言うとCDNで、S3などのオリジンサーバーに存在する静的コンテンツをキャッシュして、効率的かつ高速に配信してくれるサービスです。
Amazon CloudFront は、ユーザーへの静的および動的ウェブコンテンツ (.html、.css、.js、イメージファイルなど) の配信を高速化するウェブサービスであり、CloudFront ではエッジロケーションと呼ばれるデータセンターの世界規模のネットワークを通じてコンテンツが配信されます。CloudFront を使用して提供されているコンテンツをユーザーがリクエストすると、そのユーザーはエッジロケーションにルーティングされます。エッジロケーションでは最も低いレイテンシー (遅延時間) が提供されるので、コンテンツは可能な最高のパフォーマンスで配信されます。
ここでキャッシュという言葉が出てきましたが、そもそもキャッシュとは、一度表示したデータを保存しておき、次に同じデータを表示する際に処理を省略することで、表示を高速化する仕組みのことです。
キャッシュには大きく分けてサーバー側でキャッシュするものと、ブラウザ側(ローカル)でキャッシュするものの2つがあり、CloudFrontが担当するのは前者にあたります。CloudFrontを使う際に後者を有効にするには追加で設定が必要なのですが、こちらについては後程説明します。
S3バケットに対してCloudFrontを使ってみる
では実際の設定方法について見ていきます。とはいっても他に解説されているサイトがたくさんあると思うので基本的にその通りにやるだけです。自分は下記サイト様を参考にしました。 www.wakuwakubank.com
以下がCloudFrontを設定しない場合のレスポンスで、

以下はCloudFrontを設定した場合のレスポンスです。

レスポンスヘッダーに X-Cache , Via などが追加されていることがわかると思います。
X-Cache の値が Hit from cloudfront となっている場合、CloudFrontがキャッシュしていることを示しています。
CloudFront キャッシュ動作確認 - Qiita
わかりやすいようにgif動画にしてみました。一度目のリクエストには多少時間がかかっていますが、二度目のリクエストはキャッシュされており即返ってきているのがわかると思います。

一点気を点けなければいけない点として、S3のリージョンを ap-northeast-1 とかに設定していると、リクエスト時に以下のエラーが返ってくる場合があります。
<Error><Code>TemporaryRedirect</Code><Message>Please re-send this request to the specified temporary endpoint. Continue to use the original request endpoint for future requests.</Message><RequestId>A4DBBEXAMPLE2C4D</RequestId>
以下でわかりやすく解説されていますが、これはCloudFrontのドメイン名にリージョン名を追加することで解決します。単純に更新が反映されるまでしばらく待つのでも問題はないみたいです。 dev.classmethod.jp
Lambda@Edgeでブラウザキャッシュを有効にする
CloudFrontを通すことでサーバーキャッシュが有効になりましたが、ブラウザキャッシュまで有効になったわけではありません。キャッシュの項で貼ったリンクを読んで頂ければわかるのですが、そもそもブラウザキャッシュを有効にするためにはレスポンスヘッダーに Cache-Control か Expires が含まれている必要があり、オリジンサーバーにEC2のApacheやNginxなどを指定している場合はそれらで設定できますが、S3の場合はCloudFrontが勝手に設定してくれたりはせず、追加で設定を行う必要があります。
S3のオブジェクトに対してブラウザキャッシュを有効にする(=レスポンスヘッダーに Cache-Control が含まれるようにする)方法としては、まずオブジェクトのメタデータを編集する方法があります。例えば以下のように設定することで

以下のようにヘッダーに Cache-Control が含まれるようになります。

この設定はオブジェクト単位であり、全てのオブジェクトに同じメタデータを追加したい場合は逐一設定するか、何かしらのスクリプトを組み一括で操作するしかありません(AWSコンソール上から一括で設定する方法はない)。
いずれにせよ面倒ですが、別の方法としてLambda@Edgeを使うことで、すべてのS3オブジェクトに対してヘッダーを設定することができます。
Lambda@EdgeとはAWS Lambda の拡張機能で、CloudFront が配信するコンテンツをカスタマイズする関数を実行できるコンピューティングサービスです(出典:公式ドキュメント)
なお選択できるリージョンがバージニア北部(us-east-1)に限られるなど色々制約があったりはします。使い方については以下の記事が詳しいと思います。 qiita.com
実際に使うには、AWSコンソールからLambda>関数の作成 を選び、設計図からcloudfront-modify-response-header というものを選びます。(リージョンがバージニア北部となっていることに注意してください。ほかのリージョンだと検索候補に出てきません)

実行するロールを選びます。

関数コードには以下のように記述します。cache-control ヘッダが存在しない場合に設定するコードです。比較のためmax-age=7200としています。
'use strict'; exports.handler = (event, context, callback) => { const response = event.Records[0].cf.response; if(!response.headers['cache-control']) { response.headers['cache-control'] = [{ key: 'Cache-Control', value: 'max-age=7200' }]; } callback(null, response); };
アクション>Lambda@Edgeへのデプロイからデプロイします。
CloudFrontイベントにはビューアーレスポンスを設定してください。

なおこのとき、実行ロールによっては、以下のエラーが表示されることがあります。
関数の実行ロールは、edgelambda.amazonaws.com サービスプリンシパルによって引き受け可能である必要があります。

ドキュメントをよく読まなかったせいで少し悩んだのですが、以下にちゃんと書いてあります。 docs.aws.amazon.com
実際には実行するロールの信頼関係が以下のようになっていなければなりません。edgelambda.amazonaws.com が欠けていると上記エラーが表示されます。


メタデータを削除し、CloudFrontのキャッシュを削除してから再度試してみると、期待通りにヘッダーが追加されていることがわかります。

CloudFrontの設定画面を見ると以下の通りにLambda関数が設定されています。逆に言えばこの画面からでもLambdaを設定することができます。

おわりに
せっかくなんでAWSの資格取れればいいなぁと思ってたまに勉強したりはしているのですが、やはりただ知識を詰め込むのではなく実際に手を動かすのが一番勉強になりますね。ちなみに書籍では以下の本を買ったんですが割とわかりやすかったです(アフィリンクとかではありません)。
AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト | 佐々木 拓郎, 林 晋一郎, 金澤 圭 | コンピュータ・IT | Kindleストア | Amazon